📰 Publish Your Data#
In this final installment of the quick start tutorial, you will learn how to take any dataset you've created, and publish it so that you can access it programmatically.
Why Publish Data?
DataDistillr is a great tool for data exploration, but sometimes there are cases where you'll need outside tools. By publishing your dataset, you can easily move it into a Pandas, PySpark or R dataframe for machine learning.
Publishing Data#
After you've run a query, in the top bar, you can click the Manage API Access button as shown below.
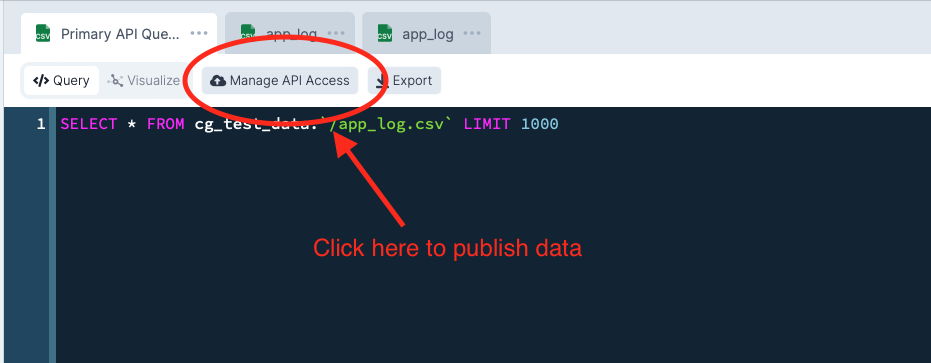
Manage API Access#
The Manage API Access page is where you can control access to the various datasets you have created.
!!! warning When you publish a dataset, anyone with the access information can view the data. Exercise caution, and protect the access tokens to prevent unauthorized access.
Create an API Access Client#
Since this is your first project, you will have to create an API Access Client. Enter a name and enable the API app.
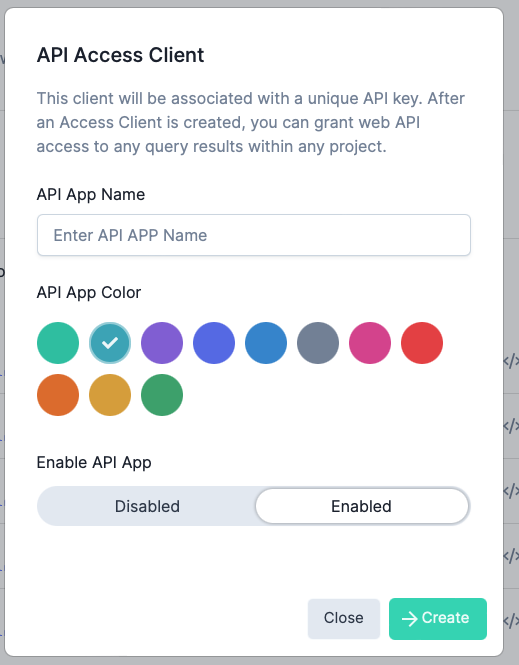
Manage API Permissions#
When you create an API Access Client, all of your projects and queries within those projects will be visible. You can set permissions for each of these to allow, deny, or inherit API access to your datasets. Inherit means the dataset will inherit the permission from the project.
!!! info Users must have an access token to access the data. Publishing a dataset does not automatically make it accessible to the public.
You can expand a project tab and see all the queries in a project. From there, you can set the access permissions for every dataset resulting from a query and view API usage statistics.
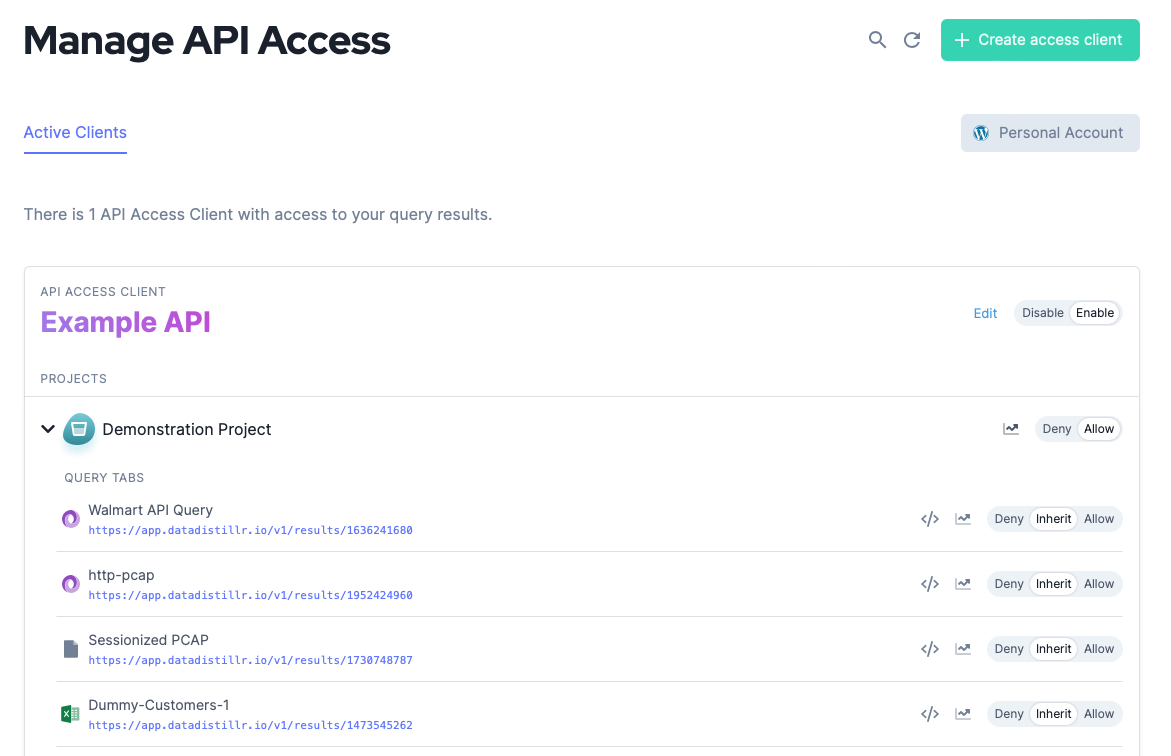
Access Published Data#
Once you've published your data, you can access this data programmatically. To retrieve the access tokens and code
snippets, click on the </> icon next to the permissions. DataDistillr will generate code snippets,
pre-populated with your API key and data set ids. All you have to do is copy and paste this code into your Python or R
scripts.
For example:
import pandas as pd
import requests
url = "https://app.datadistillr.io/v1/results/<dataset id>"
api_key = "<YOUR API KEY HERE>"
headers = {"Authorization": api_key}
response = requests.get(url, headers=headers)
data = pd.DataFrame(response.json()['results'], columns=response.json()['summary']['columnNames'])
library(dplyr)
library(httr)
library(data.table)
URL <- "https://app.datadistillr.io/v1/results/<dataset id>"
AUTH_HEADER <- "<YOUR API KEY>"
response <- GET(URL, add_headers(Authorization = AUTH_HEADER))
content <- content(response, as = "parsed", type = "application/json")
data <- data.frame(rbindlist(content$results))
colnames(data) <- content$summary$columnNames
That's it!